AI 视频生成是通过扩散模型(Diffusion Models) own 或自回归变换器(Transformers)将文本、图像或视频片段转化为动态视觉内容的计算过程。其核心逻辑在于通过海量数据训练,使模型在概率分布中模拟物理世界的运动规律与视觉语义。到 2026 年 3 月,AI 视频已从早期的短片段抽搐感,进化到能够支撑电影级长镜头与精准物理模拟的阶段。
目前的 AI 视频并非简单的像素堆砌,而是对现实世界的概率模拟。这意味着虽然几个词就能生成极具视觉冲击力的画面,但要精准掌控每一帧光影,仍需特定的工作流。很多社交媒体上的惊艳片段,本质上是数百次随机抽卡的筛选结果,而非一次性生成的成品。
核心技术:从潜在扩散到时空令牌化

顶尖模型已全面转向时空潜在块(Spacetime Patches)处理方式。模型不再将视频视为连续的图片序列,而是将其切分成三维的“小方块”。通过在潜在空间预测这些积木的分布,模型能显著提升生成的一致性,减少物体凭空消失或变形的概率。
这种架构在 2026 年解决了长期存在的快照一致性问题。通过增强的注意力机制,模型能锁定关键特征的 ID 令牌,确保在 60 秒的镜头中,人物面部和环境细节保持恒定。但在处理极高速运动(如赛车疾驰)或复杂物理交互(如液体溅起)时,由于模型对流体力学缺乏真实物理计算,依然会出现逻辑断层。
主流工具能力分层与选择建议
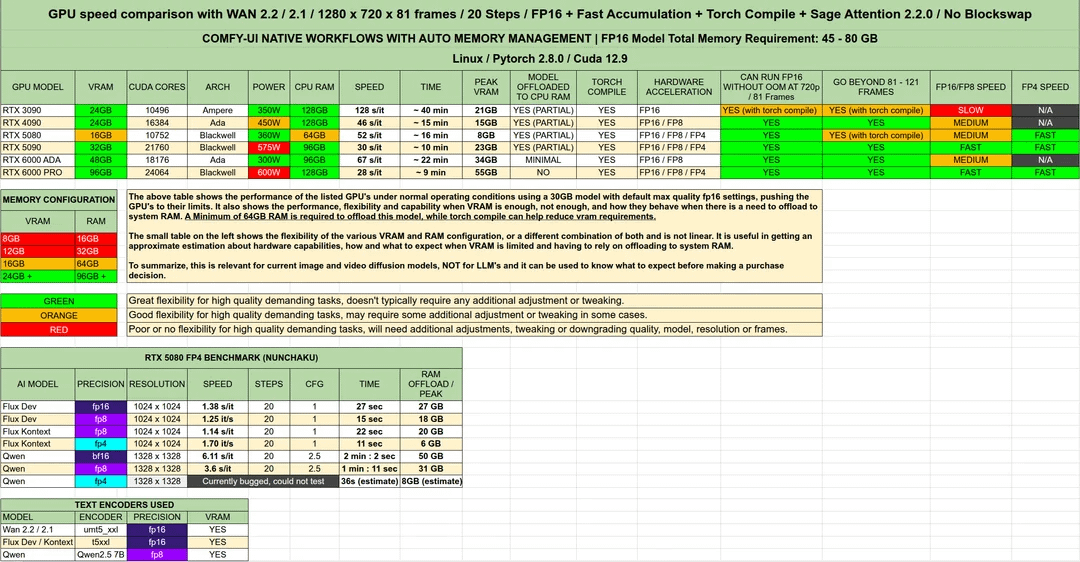
根据视觉质量、生成速度与指令遵循度,目前的 AI 视频工具呈现明显的阶梯分布。创作者应根据项目对“电影感”或“出片效率”的需求选择合适的工具链。
| 工具名称 | 核心优势 | 适用场景 | 成本/门槛 |
|---|---|---|---|
| Sora 2 | 视觉天花板,长镜头稳定,复杂运镜 | 高质量广告、概念电影预演 | 企业级订阅,成本较高 |
| Kling 2.6 | 动作幅度自然,光影捕捉出色 | 社交媒体短视频、人物动态 | 中等(月费 $20-100) |
| Wan 2.6 / HAILUO | 极速生成,高指令遵循度 | 快速原型创作、视觉尝试 | 较低 |
| Higgsfield / OpenArt | 多模型聚合,素材丰富 | 大规模素材剪辑 | 社区驱动 |
实操工作流:如何生成可商用的品牌宣传片
采用“图像-视频(I2V)”工作流是获得商用级结果的最可靠路径。直接依赖 Text-to-Video 的随机性过高,无法满足商业交付的精准度要求。
deformed limbs 或 morphing 以减少畸变。
版权风险与技术边界
版权是 AI 视频最大的法律雷区。由于 AI 是对训练数据的概率拟合,若生成内容与特定艺术家作品高度相似,工作室将面临风险。建议优先使用自有版权数据集模型或在后期进行深度修改(Overpainting)。
目前 AI 视频仍存在三大技术局限:
- 物理逻辑缺失:无法完全理解 3D 空间遮挡,易出现物体融化现象。
- 时间控制粗糙:无法实现毫秒级的精确动作触发(如指定在 3.5 秒眨眼)。
- 语义漂移:长视频容易在过程中忘记初始设定,导致场景环境发生非预期变化。
不建议使用 AI 视频的典型场景:
- 工业产品演示(缺乏 CAD 物理支持,精密运转易出错)。
- 极致情感特写(易产生恐怖谷效应,缺乏潜台词微表情)。
- 零后期能力项目(迭代成本过高,实拍效率更高)。
如何有效掩盖 AI 视频的视觉瑕疵?
建议采用“快速切镜”的剪辑逻辑。通过缩短单个镜头的时长,在瑕疵出现之前进行转场,并结合环境音效和背景音乐增强整体沉浸感,从而转移观众对局部逻辑错误的注意力。
I2V 比T2V 的核心优势在哪里?
I2V(Image-to-Video)提供了视觉锚点,允许创作者在视频生成前先通过 AI 绘图工具精准控制构图、色彩和角色形象,从而将“随机抽卡”的概率降低,显著提升了商用场景下视觉语言的一致性。
AI 视频生成目前能完全替代实拍吗?
不能。AI 目前擅长的是“视觉模拟”而非“物理还原”。在需要极其精确的物理交互、品牌特定产品细节或深层情感表达的场景中,实拍依然是唯一标准。目前的最佳实践是“AI 辅助实拍”或“混合工作流”。
行动建议:建立“混合工作流”。不要试图用一个工具解决所有问题,将 Midjourney 的审美、Kling 的动态、Topaz 的画质与 Premiere 的剪辑组合在一起。先尝试从 15 秒短片开始,强制使用 I2V 流程,在实践中通过快速切镜掩盖 AI 瑕疵,将竞争力从 Prompt 技巧转向镜头语言和故事结构。