AI 翻译是指利用大型语言模型(LLM)或神经机器翻译(NMT)技术,通过计算概率和模式识别将一种语言转换为另一种语言的自动化过程,它已从简单的词对词映射演变为基于上下文理解的语义重构。到 2026 年 3 月,AI 翻译的重心已经从单纯的“准确度”转向了“语境适配度”和“文化对齐”。
AI 翻译并不真正“理解”语言,其本质是在预测目标语言中统计学上最可能出现的下一个词。这意味着在处理冷门专业术语或深层情感隐喻时,AI 仍可能出现“幻觉”;但对于 80% 的日常商业、技术文档和通用沟通,AI 已经达到了无需再次校对的临界点。
AI 翻译的生态格局与核心差异
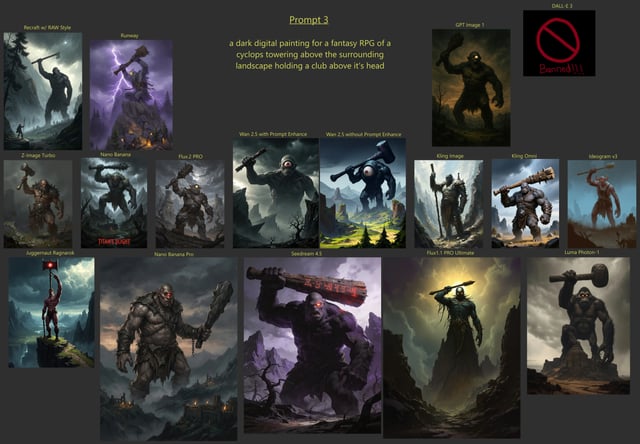
目前的 AI 翻译生态被分为三大阵营,各具优势且适用场景不同:
| 阵营 | 代表工具 | 核心优势 | 适用场景 |
|---|---|---|---|
| 专业翻译工具 | DeepL | 语法自然度极高,欧洲语系精准 | 高频次文档翻译、商务往来 |
| 通用大模型 | GPT-5 / Claude 4 | 强大的风格转换与语境理解 | 创意翻译、风格适配、复杂语义重构 |
| 实时口译系统 | 集成硬件设备 | 极低延迟,端到端语音转换 | 跨国会议、实时旅游沟通 |
要真正发挥 AI 翻译的威力,不能直接把文本丢进去,而必须采用“提示词工程 + 迭代校正”的链路。以下是针对专业翻译场景的一套具体实操方案。
第一步:构建结构化的上下文提示词(Contextual Prompting)
结论:通过创建包含“角色-目标-领域-限制”的模版,可以有效解决 AI 翻译缺乏语境、结果机械的问题。
2. 提供背景: 明确受众群体(如“面向专业医生”或“面向患者”)。
3. 设定约束: 给出风格要求(如“避免被动语态”、“符合 2026 年国际医学标准”)。
一个具体的参数配置示例:
- 任务:医学论文摘要翻译
- 风格:学术、克制、精准
- 禁忌:禁止将 'significant' 统一翻译为 '显著的',需根据统计学语境判断是 '意义重大' 还是 '具有统计学差异'
- 预期结果:输出两版本,版本 A 为直译,版本 B 为符合学术期刊发表习惯的意译。
第二步:实施“双向回译”验证法(Back-Translation Verification)

结论:回译闭环是验证法律、财务等高精度领域翻译准确性的最有效手段,能将错误率降低 40% 以上。
2. 隔离回译: 开启一个全新的对话会话(消除记忆偏差),将 B 再次翻译回 A'。
3. 语义比对: 对比 A 与 A'。若核心语义出现偏差,则 B 版本存在风险。
4. 精准修正: 将差异点反馈给 AI,要求其解释并强制使用特定术语替换。
第三步:利用 RAG(检索增强生成)构建私有术语库

结论:通过搭建轻量级 RAG 系统或使用自定义 GPTs,可以强制 AI 在翻译前检索企业标准词典,确保术语统一。
2. 向量化存储: 上传至向量数据库或自定义 GPTs 知识库。
3. 检索注入: 在翻译触发时,系统先检索相关术语作为“参考事实”注入 Prompt。
4. 优先调用: AI 优先采用文件中的定义,而非基于概率随机生成。
AI 翻译的局限性与未来竞争力
尽管技术飞跃,但在以下三种场景中,AI 依然表现得像个“门外汉”:
- 文化潜台词: 如中国诗词的“意象”,AI 能译出字面意思,但难以还原文化共鸣。
- 高风险实时决策: 如手术室指令或外交措辞,细微的统计学偏移可能导致严重后果。
- 低资源语种: 缺乏足够语料的方言或小语种,经常出现语法崩溃。
未来的翻译竞争力将不再是单词量的记忆,而是引导 AI 生成高质量文本的能力以及在海量译文中瞬间识别 1% 错误的能力。翻译人员的职能正在从“搬运工”转变为“编辑”和“审核员”。
如何选择最适合自己的 AI 翻译工具?
高频次文档翻译建议使用 DeepL 专业版(约 20-30 美元/月);需要灵活风格切换的用户建议使用通用 LLM 订阅版(约 20 美元/月);开发者建议通过 API 按 Token 计费集成到工作流中。
面对大量外语资料,最快捷的上手路径是什么?
建议先从建立自己的“术语提示词库”开始,将复杂文档拆分成小段,跑通“上下文注入 $\rightarrow$ 翻译 $\rightarrow$ 回译验证”的链路,将 AI 视为一个勤奋但需要监督的助手,即可实现效率的量级提升。